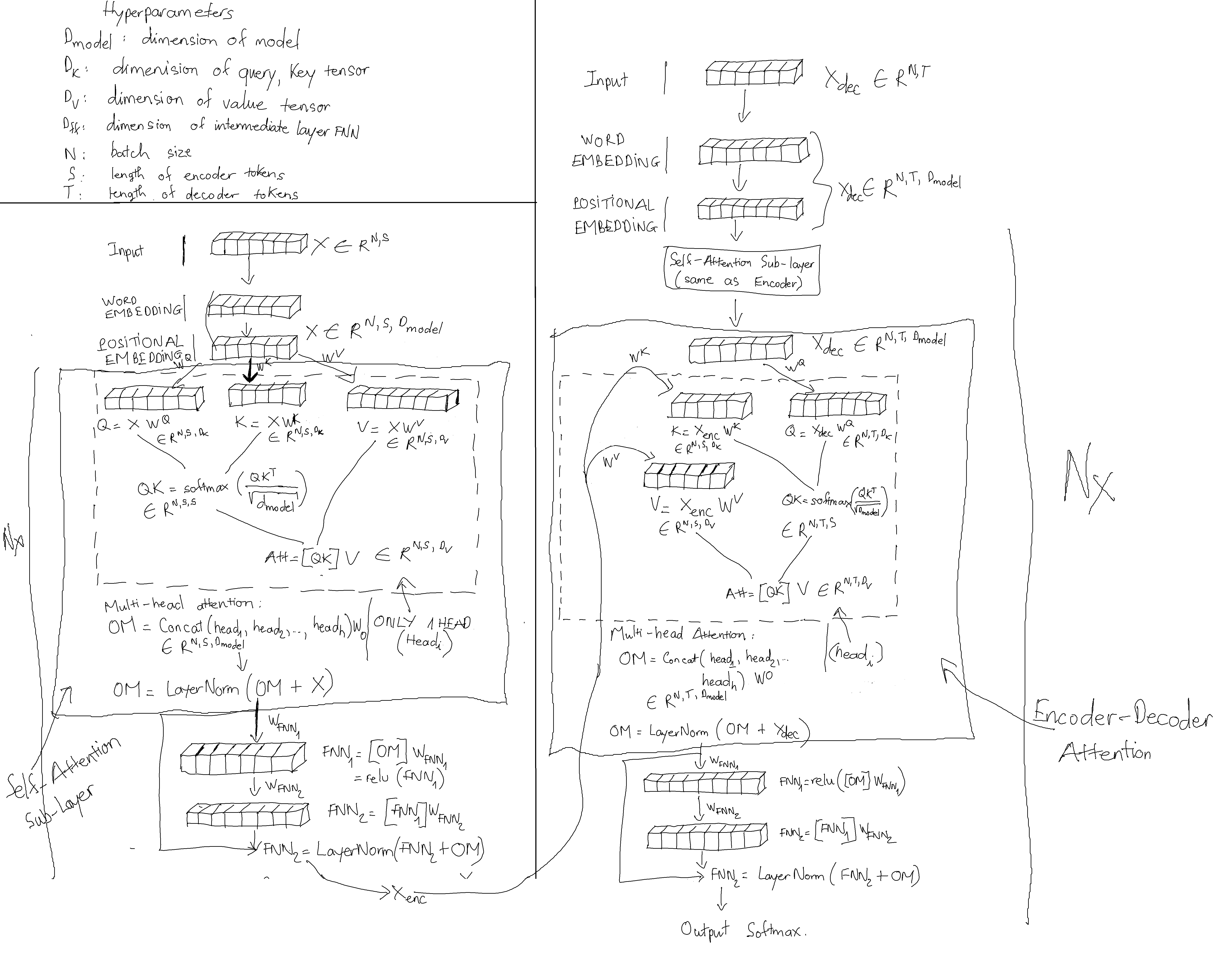
Transformer is a breakthrough NLP model, it completely depends on attention mechanism (eliminates convolutional and recurrent neural network). It is the core/backbone that build up many state-of-the-art models: BERT, XLNet,… It also utilizes the use of parallelism to speed up training.
The key features in Transformer:
- Self-Attention Layer.
- Cross-Attention Layer (Encoder-Decoder Attention Layer).
- Positional Embedding.
- Layer Normalization.